
Technical Overview: The AI Architecture Behind Sora 2's Realistic Video and Audio Generation
Sora 2 represents a significant advancement in AI-driven video and audio generation, building upon a sophisticated architecture that combines multiple cutting-edge machine learning techniques. Released as OpenAI's flagship video and audio generation model, Sora 2 achieves unprecedented realism through its integrated approach to world simulation, physics modeling, and synchronized multimedia output.
Core Architecture Components
Diffusion and Transformer Foundation
At its foundation, Sora 2 employs a hybrid architecture combining diffusion models with transformer-based systems. The model uses a Spatiotemporal Autoencoder that compresses video frames into latent representations, significantly reducing computational overhead while preserving critical details like motion and texture. This compression is paired with a Diffusion Transformer (DiT) backbone for denoising and generation, which replaces traditional U-Net designs to better handle long sequences and enable cinematic outputs.
Multimodal Diffusion Transformer (MM-DiT)
The Multimodal Diffusion Transformer represents a key architectural innovation, integrating text, image, and audio inputs to ensure synchronized outputs. Unlike earlier systems that treated audio as an afterthought, this component enables the model to generate dialogue that lip-syncs perfectly with character movements and creates sound effects that match visual events frame-by-frame.
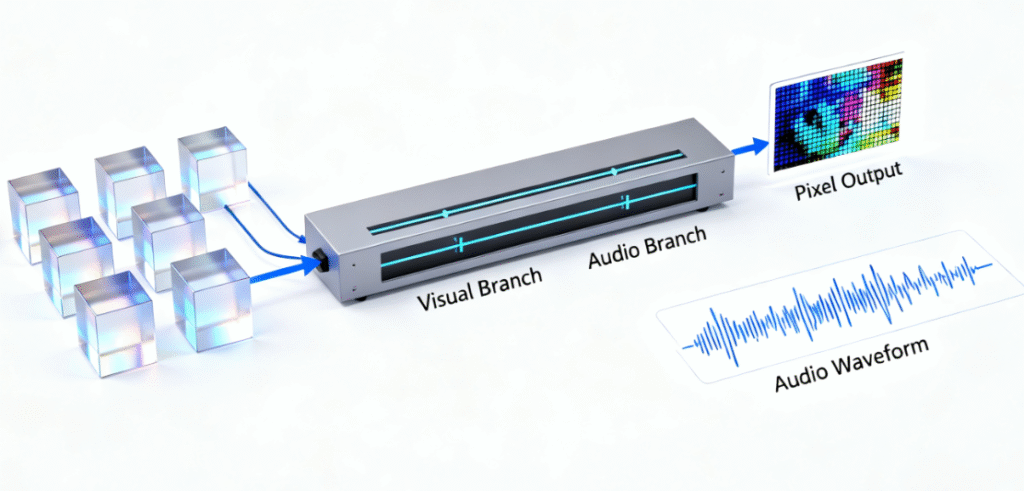
Audiovisual Decoder
New to Sora 2, the Audiovisual Decoder maps latent representations back to both pixel data and audio waves, enabling synchronized generation. The decoder processes both visual tokens and text-derived audio cues (such as "rain sound + distant thunder"), with spatial audio logic baked in—if a car moves left across the screen, its engine sound shifts accordingly to create an immersive experience.
Advanced Capabilities and Enhancements
Physics Correction Loop
Sora 2 incorporates a sophisticated Physics Correction Loop featuring a "referee model" that identifies errors such as floating objects or unnatural movements and feeds them back for retraining. This mechanism ensures that complex physical interactions—like a missed basketball bouncing off the rim realistically or a glass shattering naturally when falling from a table—are rendered with accuracy. The model's enhanced physics understanding enables more complex and dynamic scenes that would have been impossible with previous generations, with improved modeling of gravity, collisions, and fluid dynamics.
Instruction Tuning and Preference Alignment
Borrowed from GPT's training methodology, Sora 2 employs Instruction Tuning and Preference Alignment where the model learns from director-like scripts (such as "low-angle shot of a running dog on a grassy field") and receives feedback on what appears natural. This approach enables the model to actually follow framing instructions rather than guessing, providing enhanced creative control including detailed prompt understanding for studio shots, scene details, and camera angles.
Temporal Coherence and Motion Consistency
The architecture maintains temporal coherence across frames through improved mechanisms for maintaining state and enhanced attention mechanisms that help the model understand long-range dependencies in video sequences. When a person walks, their weight distribution and movement patterns appear natural; when objects collide, the interaction looks physically plausible. This temporal consistency is achieved through diffusion models and transformer architectures specifically adapted for video generation.
Inference Efficiency Optimizations
Sora 2 achieves remarkable speed through several engineering innovations. The model reuses FLUX model initialization, cutting training time significantly by leveraging pre-trained components rather than starting from scratch. Additionally, high-compression 3D autoencoders with a 4×32×32 compression ratio reduce inference time by 10x, enabling the generation of a 10-second clip in seconds rather than minutes.
Advanced Features
Face Scanning and Likenesses
One of Sora 2's most impressive capabilities is its ability to accurately recreate human faces and likenesses through face scanning technology, achieving approximately 90% accuracy in replicating facial features, expressions, and subtle details like skin texture and lighting reflections.
Synchronized Audio and Dialogue
Sora 2 produces frame-accurate audio with dialogue, footsteps, and effects that match the scene. The model generates sophisticated background soundscapes, speech, and sound effects with high realism, with audio available in multiple languages. Independent observers describe its output as "highly realistic" with improved object permanence and motion physics, with PC Gamer testing confirming that Sora 2 creates live-action human clips with synchronized audio.
Enhanced Controllability
The model demonstrates a major leap forward in controllability, able to follow intricate instructions spanning multiple shots while accurately persisting world state. It excels at realistic, cinematic, and anime styles, with improved prompt handling and scene transitions refined through training on vast datasets of internet-scale videos and audio.
Training and Data Methodology
Sora 2's improvements reflect advances in training methodology, incorporating more diverse and higher-quality video data that enables the model to learn more nuanced patterns about how the world works. The training process uses improved loss functions that penalize physically implausible outputs, ensuring that the generated content adheres to real-world physics principles. While exact parameter counts remain proprietary, Sora 2's efficiency suggests optimizations like mixture-of-experts architectures, enabling faster inference on consumer hardware.
This comprehensive architectural approach positions Sora 2 as a significant milestone in video generation technology, representing what OpenAI describes as potentially the "GPT-3.5 moment for video"—capable of generating content that was previously exceptionally difficult or impossible for prior systems.
















Maple Ranking offers the highest quality website traffic services in Canada. We provide a variety of traffic services for our clients, including website traffic, desktop traffic, mobile traffic, Google traffic, search traffic, eCommerce traffic, YouTube traffic, and TikTok traffic. Our website boasts a 100% customer satisfaction rate, so you can confidently purchase large amounts of SEO traffic online. For just 720 PHP per month, you can immediately increase website traffic, improve SEO performance, and boost sales!
Having trouble choosing a traffic package? Contact us, and our staff will assist you.
Free consultation